
| WORD | OCCURANCE |
|---|---|
| elizabeth | 635 |
| could | 527 |
| will | 424 |
| darcy | 418 |
| bennet | 333 |
| bingley | 306 |
| jane | 295 |
| sister | 294 |
| lady | 265 |
| time | 224 |
| well | 224 |
| good | 201 |
| wickham | 194 |
| great | 187 |
| collin | 180 |
| day | 178 |
| young | 177 |
| dear | 175 |
| lydia | 171 |
| hope | 169 |
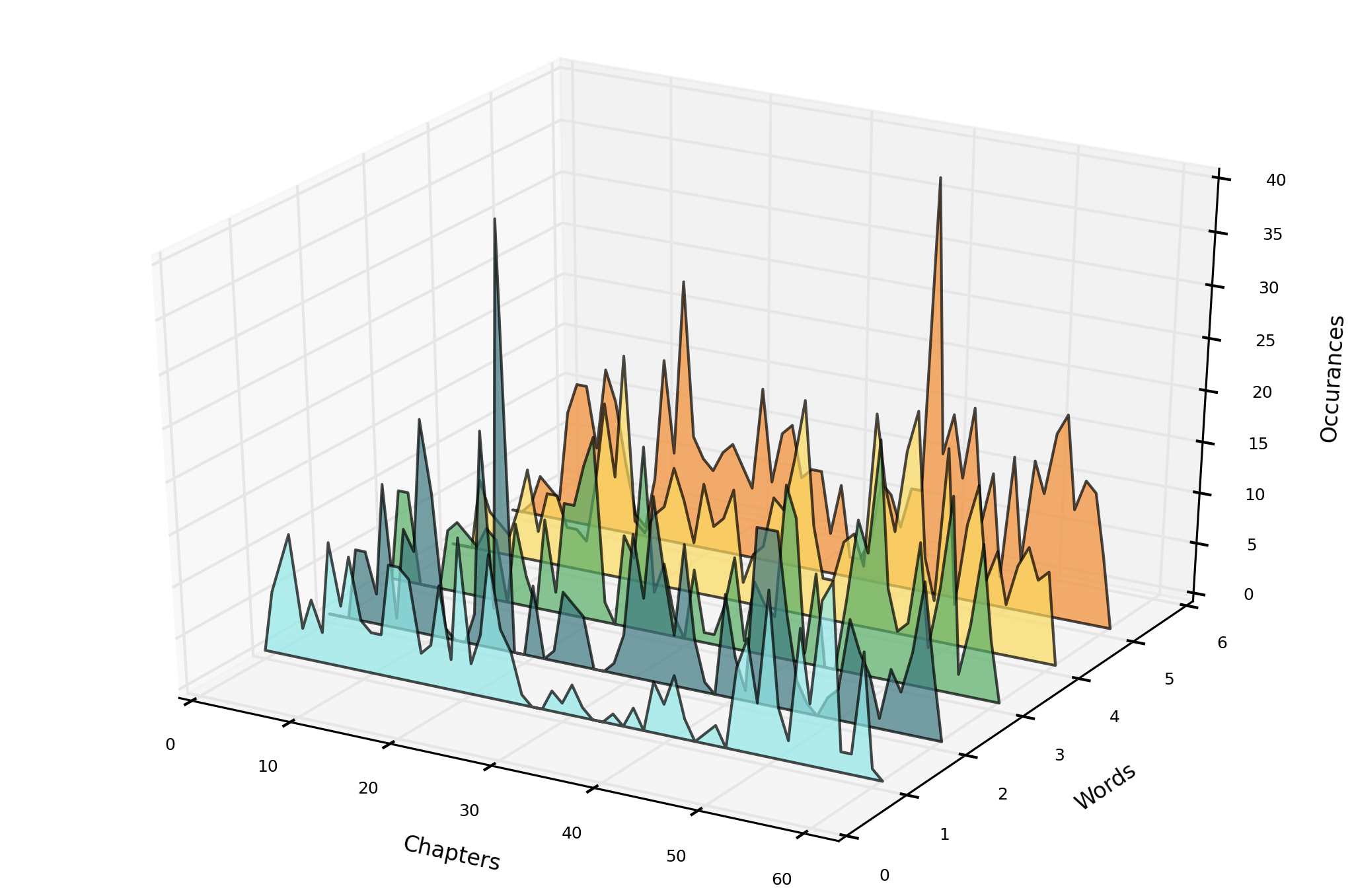
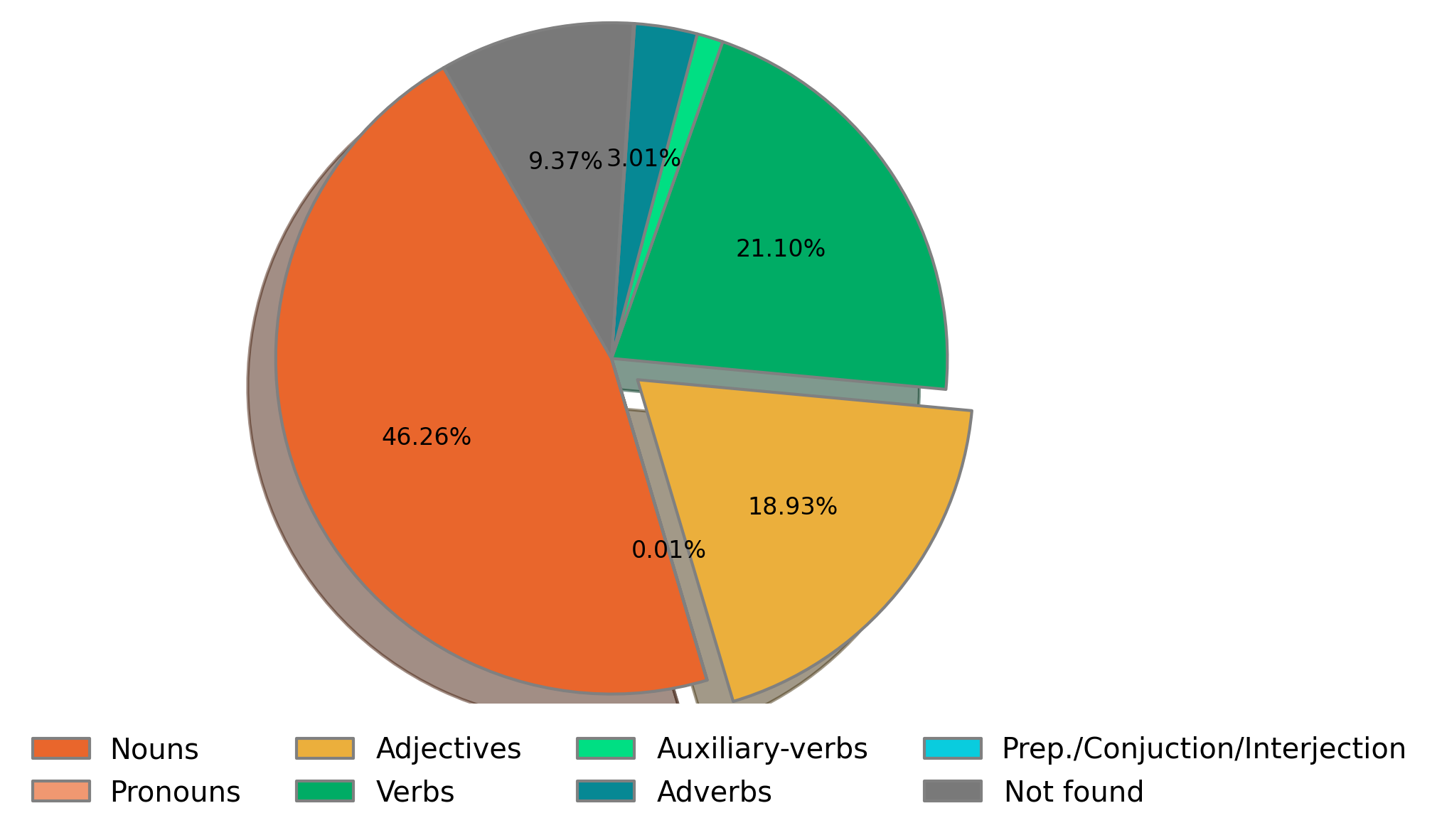
Part of speech tagging is an interesting breed: mostly all longer texts split up into a quite constant array of nouns / verbs / etc. - no surprise here!What's more interesting when you combine part of speech tagging with other forms of analysis. Would the occurences of only adjectives tell us more about the mood of a certain part of text, like a chapter? Certainly so! What about verbs? Do they present traces of action and happening?Part of speech tagging becomes especially helpful when playing with n-grams and sentiment analysis, so for now just take our word: the application is ready to bring 100.300 English words for tagging, there can not be a lot more than that!These features will be coming out soon on Underminer. Until then, part of speech tagging is displayed in a form of the good old boring piechart.